(Draft) Writing a differentiable fluid solver in Julia
A journey from sparse matrices in MATLAB to differentiable GPU operators in Julia

IncompressibleNavierStokes.jl is a Julia package for solving the Incompressible Navier-Stokes equations given by
where

The velocity field is defined on the volume faces, and the pressure in the volume centers. The grid is Cartesian, but the volumes are allowed to have non-uniform sizes. This discretization is useful since the divergence constraint
Initial implementation: Sparse matrices
My PhD supervisor wrote an implementation a while back in MATLAB, using sparse matrices. The matrix equations equations take the following (integral) form:
where
Matrices are very convenient to work with, since the code is identical to the mathematical matrix formulation. We never have to consider velocity components individually, and the code is very readable. MATLAB also requires us to write it in this way for performance reasons, and if you do so MATLAB is very fast. Since Julia and MATLAB syntax are very similar, translating the implementation to Julia was trivial.
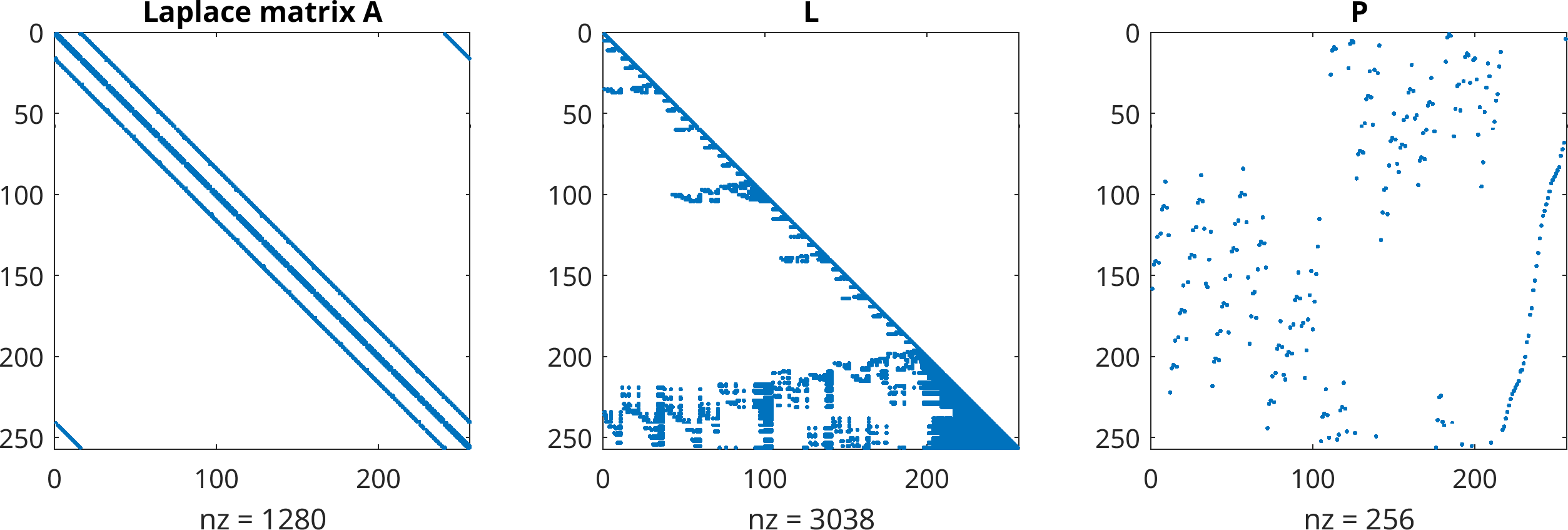
Sparse matrices can also be fully factorized, for example using an LDLt decomposition for the symmetric Laplacian matrix
Additionally, using sparse matrices made it trivial to extend the Julia implementation with two features: differentiability and running on GPUs. Chain rules are already provided for common matrix operations in Julia. As a result, the matrix implementation could be made reverse-mode differentiable with minimal effort (making sure not to modify arrays anywhere in the computational chain). I use this to optimize closure model coefficients while embedded in the solver. CUDA.jl has all the tools for porting the code to Nvidia GPUs. The code for the matrix assembly was not easy to port, so I ended up doing the assembly on the CPU and transferring the sparse matrices onto the GPU after assembly. The actual solver code was agnostic to the array types used, so no modification was needed there. Solving implicit problems however was a bit more tricky, as I couldn't immediately find good sparse matrix factorization capabilities for the GPU. Initially while porting I did the factorization on the CPU (for solving the pressure Poisson equation), making the actual speed-up much smaller. I also tried iterative solvers, but they were not as fast as using precomputed factorizations. They also require good preconditioners, of which partial LU factorizations are good candidates (but I couldn't find this for CUDA.jl). For fully periodic cases however, the solution to the pressure Poisson equation can be explicitly written down using discrete Fourier transforms, which CUDA.jl supports out of the box. It was very pleasant to see the speed-up. Later I also found CUDSS.jl, which is not included in CUDA.jl. This provides efficient sparse factorizations.
However, I ran into problems when solving for larger 3D problems. Turbulent flows require very fine grids, but GPUs have limited memory. While the sparse matrices contain a lot of redundant information (finite difference stencils), they still require storing all the non-zero coefficients. Since the equations are solved in 2D or 3D, the finite-difference like matrices do not have an obvious multi-diagonal structure, and the only reasonable matrix type are raw sparse matrices. This led me to look into matrix-free methods.